Sample evaluation becomes a schedule risk when teams treat it as open-ended exploration instead of validation against deployment constraints. The fastest projects define what “deployment-ready” means up front, time-box each stage, and prevent scope creep from turning testing into an endless loop.
Effective sample evaluation requires staged testing with clear pass/fail criteria, time-boxed evaluation windows, and alignment between clinical, IT, and procurement stakeholders on must-pass requirements. Structure evaluation as progressive stages that reduce risk early rather than waiting for perfect final samples, and ensure every finding maps to a decision path (fix, accept, escalate, or de-scope) within 24–48 hours for triage and next-step ownership.
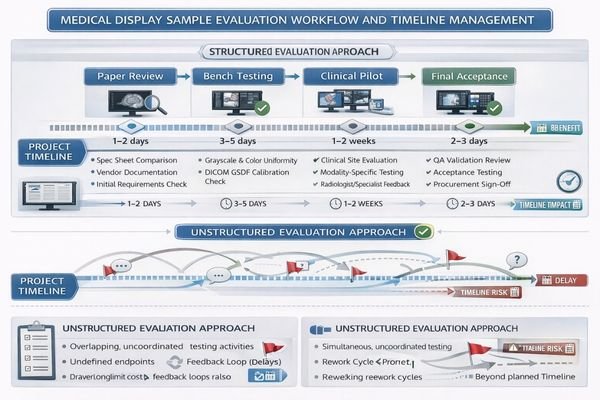
Successful evaluations treat sample testing as risk reduction rather than broad product assessment. When the scope is explicit, criteria are measurable, and configuration changes are controlled, teams can make confident decisions without sacrificing momentum—because the evaluation produces outcomes that are directly usable for deployment, documentation, and lifecycle management1.
What is "sample evaluation" in medical display projects, and why does it often delay timelines?
Sample evaluation involves structured verification that proposed monitors meet clinical expectations and integration requirements within specific deployment environments.
Sample evaluation in medical display projects is structured verification that proposed units meet clinical use expectations, integration constraints, and acceptance criteria within specific environments. Timelines slip when evaluation goals are vague, stakeholders run parallel tests without shared criteria, or sample configurations differ from deployment configurations. Delays occur when evaluation is treated as single late-stage gates instead of staged processes.
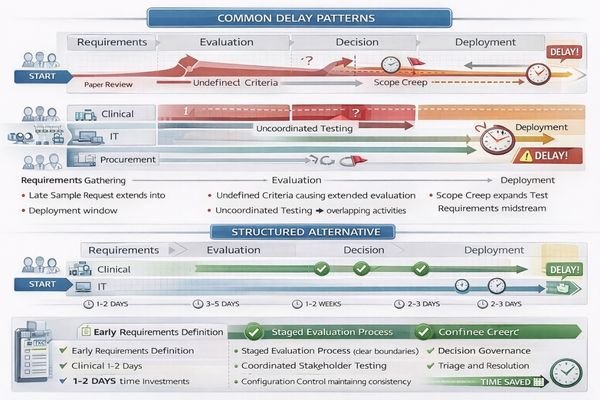
The key distinction is that sample evaluation2 is about deployability, not benchmarking. It validates whether the proposed display will behave consistently in your real workflow: the same signal chain, the same mounting method, the same cleaning routine, and the same system settings you will use after go-live. Projects fall behind when teams start testing before agreeing on what “done” looks like, or when the sample arrives configured differently than the final rollout (interfaces, routing, presets/firmware, OS/GPU settings). The schedule impact compounds because mismatches trigger rework—teams repeat tests after every configuration change, and stakeholder feedback becomes subjective because it is not tied to controlled scenarios. The fastest evaluations start with clear scope definitions, map to project milestones, and reduce rework by ensuring samples are tested under conditions that match actual rollout scenarios.
Common Timeline Risk Factors
Evaluation delays typically result from unclear success criteria, parallel testing without coordination, configuration mismatches between samples and deployment systems, and treating evaluation as exploration rather than validation of specific requirements against known deployment constraints. A reliable way to avoid this is to define the evaluation “surface area” early: which workflows are in scope (diagnostic, OR, mixed-use), which environments will be used, and which variables are allowed to change during testing.
Structured Evaluation Benefits
Systematic evaluation approaches define measurable outcomes, establish shared decision criteria across stakeholders, and ensure sample configurations match deployment specifications including signal chains, mounting systems, cleaning protocols, and operating system settings that affect clinical performance. When these inputs are fixed, results become comparable across users and system states, and the evaluation can produce a baseline package that directly supports deployment and future troubleshooting.
How do you define pass/fail criteria that prevent endless re-testing?
Effective pass/fail criteria must be measurable, role-based, and tied to workflow risk rather than subjective preferences.
Effective pass/fail criteria are measurable, role-based, and tied to real workflow risk rather than personal preference. Separate must-pass clinical safety and usability items from nice-to-have preferences, then translate each must-pass item into observable outcomes under controlled conditions. Lock rules with shared checklists, scoring methods, and predefined decision paths so findings lead to decisions rather than new experiments.

Criteria prevent re-testing only when they are specific enough to end debate. Start by defining must-pass items by stakeholder role: clinicians validate workflow fit (visibility, usability, readability) under predefined scenarios; IT validates reproducibility (signal routing, OS/GPU settings, versions, recovery behavior); procurement validates lifecycle risk (serviceability, replacement stability, documentation completeness). Then convert each must-pass item into a controlled test condition3 and an observable outcome. Replace “looks good” with statements like “under the target ambient light and viewing distance, the workflow task is readable without reconfiguration,” or “after power cycle and reconnect, the system restores the expected mode without manual intervention.” Finally, add governance so the evaluation can finish: assign a single decision owner for pass/fail, establish severity levels (P0 blocks deployment, P1 risks clinical/integration consistency, P2 is optional optimization), and require a decision path for each finding. The goal of the 24–48 hour window is not to “solve everything,” but to triage and commit to fix/accept/escalate/de-scope so the project keeps moving.
What evaluation stages keep progress moving while samples and requirements evolve?
Staged evaluation with increasing fidelity enables early risk reduction without waiting for perfect final samples.
Timeline-friendly evaluation uses staged approaches with increasing fidelity to de-risk early without waiting for perfect samples. Stage one covers paper and signal-chain reviews, stage two focuses on fit-for-integration bench testing, stage three involves limited clinical pilots, and stage four provides final acceptance aligned with deployment configuration. Each stage produces decisions and reduces uncertainty rather than postponing everything.
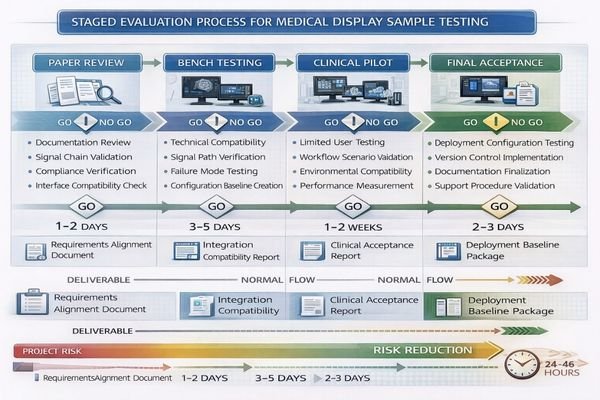
Staged evaluation maintains momentum by ensuring each phase produces actionable decisions and reduces project uncertainty rather than accumulating testing activities without clear resolution paths.
| Evaluation Stage | Focus Areas | Duration | Key Deliverables | Decision Criteria |
|---|---|---|---|---|
| Paper Review | Use cases, interfaces, compliance | 1-2 days | Requirements alignment, signal chain validation | Configuration feasibility |
| Bench Testing | Compatibility, failure modes | 3-5 days | Integration test results, compatibility matrix | Technical fit assessment |
| Clinical Pilot | Workflow fit, usability | 1-2 weeks | User feedback, performance data | Clinical acceptance |
| Final Acceptance | Deployment configuration | 2-3 days | Baseline configuration, restore procedures | Deployment readiness |
| Configuration Freeze4 | Change control | After acceptance | Version control, change management | Deployment stability |
Stage one involves paper and signal-chain reviews that confirm use cases, interfaces, mounting constraints, cleaning requirements, and validation expectations while verifying that proposed signal paths can deliver required resolution and behavior patterns. This stage should end with a clear statement of scope and a locked test plan so later findings can be interpreted consistently.
Stage two provides fit-for-integration bench testing using representative sources and routing including PACS workstations, capture devices, KVM systems, and OR processors, focusing on compatibility assessment and failure mode identification. Bench testing should deliberately include “reset moments” (reboot, cable replug, source switching) because those are common points where real deployments drift.
Stage three implements limited clinical pilots in target environments with small user groups and well-defined observation windows, collecting only data tied to must-pass criteria rather than general feedback collection. A pilot should be short, scenario-driven, and designed to answer a few high-risk questions—not to gather unlimited opinions.
Stage four is final acceptance aligned to the planned rollout configuration: the same firmware, the same presets, the same mounting method, the same accessories, and the same routing assumptions. This is where you capture the baseline package used for deployment and support—configuration snapshot, version inventory, signal-chain diagram, test results, and a restore procedure.
Configuration freeze follows acceptance and is a project control step: it freezes the evaluation scope and the deployed configuration baseline, so late changes do not restart the evaluation clock. Issues can still be handled, but any proposed change must include impact assessment and an explicit decision on whether it alters the baseline and requires re-validation.
How do you run tests efficiently across clinical, IT, and procurement stakeholders?
Efficiency requires aligning responsibilities and evidence requirements before stakeholders begin testing activities.
Efficiency comes from aligning responsibilities and evidence requirements before anyone touches samples. Clinicians validate workflow fit under controlled scenarios, IT owns technical reproducibility including settings and routing, and procurement focuses on lifecycle risk including warranty and serviceability. Use single evaluation logs with time-boxed windows and change-control rules preventing new requirements without impact assessment.
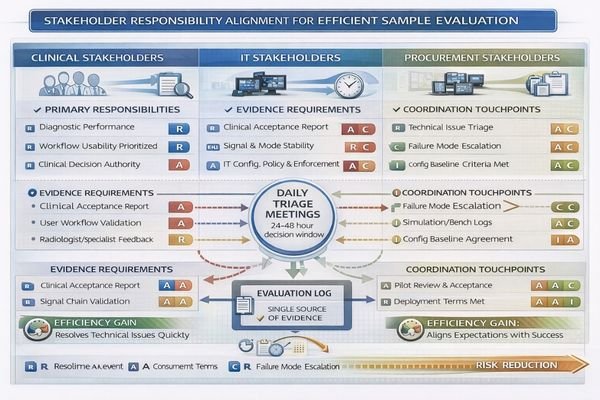
Efficiency is mostly process, not effort. Before the sample arrives, agree on (1) the scenarios to test, (2) the evidence required for sign-off, and (3) who owns each decision. Clinicians should provide feedback that is anchored to predefined workflows and must-pass items, such as readability under real ambient light and typical viewing distance, or usability with protective equipment when relevant. IT should ensure tests are repeatable by controlling OS/GPU settings, documenting driver/firmware versions, validating routing/KVM behavior, and running a consistent script that produces comparable outputs. Procurement should evaluate lifecycle risk: whether the tested configuration can be replicated at volume, what service and replacement terms look like, and whether documentation is sufficient for sustained operations.
Operationally, use a single evaluation log5 and a daily triage cadence (even a brief fixed-time review) so findings are converted into decisions quickly. Apply severity and decision paths consistently: P0/P1 findings must trigger fix/accept/escalate/de-scope within 24–48 hours for next-step ownership, while P2 items are documented and scheduled without blocking milestones. This prevents “new requirements” from being added midstream without impact assessment and keeps evaluation aligned to timeline reality.
How to choose the right medical display samples to evaluate without over-ordering
Sample selection should maximize representativeness while focusing on highest-risk workflow elements.
Effective sample selection requires strategic focus on deployment representativeness and workflow risk factors.
To avoid wasting time and budget, select samples that maximize representativeness of final deployment and stress the highest-risk parts of clinical workflows.
Clinical Scenario Prioritization
Start by choosing clinical scenarios that drive strictest requirements, distinguishing between diagnostic reading, OR visualization, and mixed-use applications, then match size and resolution to typical viewing distances and detail discrimination requirements to avoid validating unrealistic form factors. The evidence output for this step should be a short scenario matrix that maps each sample to the workflow it represents and the must-pass tasks it must support.
Integration and Interface Alignment
Align interfaces and complete signal chains by confirming exact input types, routing and KVM components, capture and recording requirements, and scaling behavior, because most project delays result from compatibility surprises rather than panel quality issues that surface during testing. The evidence output should be an end-to-end signal-chain diagram6 plus a compatibility matrix (sources, resolutions/refresh, routing modes, recovery behavior).
Physical and Compliance Constraints
Specify mounting and cleaning constraints upfront including arm compatibility, VESA patterns, cable strain relief, sealed surfaces, and disinfection routines, since these factors affect both integration time and long-term usability throughout clinical deployment lifecycles. The evidence output should be a mounting and cleaning checklist validated in the target environment (space, cabling, wipe-down routine, and handling expectations).
Configuration and Serviceability Planning
Define compliance validation and serviceability by ensuring sample configurations can be replicated in volume orders, planning firmware and preset control approaches, and confirming lifecycle support so replacements won’t introduce new behavior requiring re-evaluation of deployment decisions. The evidence output should be a baseline package template that procurement and IT can reuse: configuration snapshot, version list, restore procedure, and replacement equivalency rules.
This approach enables evaluation of fewer units with higher confidence because each sample is chosen to answer schedule-critical questions rather than providing general product assessment across broad use cases.
FAQ
How long should a sample evaluation window be to avoid dragging the project?
Time-box it by stage: short bench tests for integration compatibility, then a limited clinical pilot with predefined scenarios. Extend only when new evidence is required to decide a must-pass item—not to “observe more.”
What should be tested first when the sample arrives?
Verify the signal chain and configuration match the intended deployment (interfaces, routing, presets/firmware). Configuration mismatches are the most common cause of rework and repeated testing later.
How do we prevent stakeholders from adding new requirements mid-evaluation?
Use change control: any new requirement must include impact assessment (time, scope, re-validation) and a decision owner who approves the change and its timeline implications.
Do we need separate samples for diagnostic and OR workflows?
Often yes, because the signal chains, validation focus, and environmental constraints differ. If you must share, define which workflow is primary and explicitly accept the trade-offs.
What documentation should we produce at the end of evaluation?
A baseline package: configuration snapshot (firmware/presets), signal chain diagram, pass/fail checklist results, version inventory, and a restore procedure for updates or replacements.
How do we decide "fix vs. accept vs. escalate" quickly?
Predefine severity levels tied to must-pass criteria and deployment risk, then hold daily triage so each finding maps to a decision path within 24–48 hours for ownership and next steps.
Conclusion
Sample evaluation stays fast when it is staged, time-boxed, and tied to clear pass/fail criteria that reflect clinical risk and integration reality. Effective evaluation processes treat testing as validation against deployment constraints rather than exploration, focusing on repeatable evidence that supports deployment readiness. By defining baseline configurations early, validating signal chains before subjective viewing, and separating diagnostic, OR, and mixed-use requirements, stakeholders avoid pulling projects in conflicting directions while maintaining evaluation momentum.
At Reshin, we emphasize evaluation methodologies that protect project timelines while ensuring confident deployment readiness through systematic risk reduction and clear decision criteria. By selecting representative samples, controlling configuration changes after acceptance, and converting findings into decisions quickly through a structured triage process, healthcare organizations can reduce re-testing cycles and protect schedules while achieving the clinical validation required for successful medical display deployments across the equipment lifecycle.
✉️ info@reshinmonitors.com
🌐 https://reshinmonitors.com/
-
Exploring lifecycle management can provide insights into optimizing product deployment and ensuring long-term success. ↩
-
Understanding sample evaluation is crucial for ensuring that your project meets real-world deployment needs. ↩
-
Exploring controlled test conditions can enhance your evaluation process, ensuring reliable and valid results. ↩
-
Learning about Configuration Freeze helps maintain project stability and control, preventing scope creep and ensuring clarity. ↩
-
An effective evaluation log can streamline decision-making and improve project outcomes by tracking findings and actions. ↩
-
A well-structured signal-chain diagram is essential for ensuring compatibility and performance in medical device integration. ↩