Selecting a medical display supplier is not just comparing specifications—it is choosing a long-term partner who can keep deployments stable across batches, sites, and years.
The best supplier selection approach is evidence-driven: weight requirements by use case, define measurable KPIs, request a minimum evidence pack, validate with multi-unit real-environment testing, and lock reliability into SLAs and change-control terms.

Supplier selection success depends more on operational controls and accountability than on first-sample impressions or pricing alone. A structured evaluation1 reduces rollout surprises, improves fleet consistency, and makes long-term support predictable as rooms, workflows, and technology evolve.
Start with use-case weighting, not a one-size-fits-all checklist
Clinical environment requirements vary significantly, making supplier evaluation criteria dependent on specific operational priorities and risk tolerance levels.
Different clinical environments prioritize different failure modes, so supplier evaluation must be weighted by where and how the display will be used rather than treated as a generic checklist.
Clinical teams and engineering teams often define “reliable” differently. OR/endoscopy deployments typically prioritize signal-chain stability2, predictable behavior during switching and movement, and minimal perceived latency during rapid motion. Diagnostic reading environments typically prioritize unit-to-unit consistency, calibration discipline, and repeatable QC workflows. Clinical review and ward implementations often prioritize uptime, rapid replacement, and practical service coverage.
Environment-Specific Priority Framework
Before evaluating suppliers, define the top failure modes that cannot be accepted in your environment, then assign weights to the evaluation criteria accordingly. The goal is to ensure the shortlist reflects operational reality rather than vendor marketing emphasis.
A simple weighting template can be:
- OR / endoscopy: stability under switching and movement, predictable latency feel, cleaning and mounting resilience
- Diagnostic reading: unit-to-unit consistency, QC workflow repeatability, documentation and re-validation readiness
- Clinical review / wards: uptime and fast swap, spares availability, predictable lead times and lifecycle continuity
Operational Risk Assessment and Weighting
Once weights are defined, your evaluation becomes clearer: the same supplier may be acceptable for a ward deployment but risky for a complex OR chain, or excellent for diagnostic consistency but slow to service in regions where turnaround time matters most.
Define a supplier scorecard with measurable KPIs and acceptance thresholds
Measurable performance indicators transform subjective supplier evaluation into objective assessment and ongoing relationship management.
A supplier scorecard should turn “reliability” into trackable KPIs with clear acceptance thresholds so performance can be evaluated during selection and governed after deployment.
Use a small set of KPIs that reflect operational reality:
| KPI area | What to measure | How to verify |
|---|---|---|
| Delivery | On-time delivery and lead-time variance | PO history, lead-time reporting, variance trends |
| Field quality | RMA rate and common failure patterns | RMA logs, failure categorization, trend reviews |
| Repair and replacement | MTTR (repair/replace turnaround)3 | SLA targets, service records, regional capability |
| Spares | Availability and lead times for critical parts | Spares policy, stocking model, lead-time commitments |
| Change control | PCN/ECN lead time and impact clarity | PCN template, notice policy, sample impact statement |
| Documentation | Completeness and revision control | Revision history, document set review, audit usability |
Define acceptance thresholds appropriate to your criticality and scale, then set a reporting cadence that makes governance routine. This prevents supplier performance from becoming a subjective conversation and helps catch drift early.
Request a minimum evidence pack before samples or pricing decide the outcome
Evidence validation should precede sample testing and pricing negotiations because many supplier failures stem from documentation and governance inadequacies rather than product performance issues.
Request a minimum evidence pack that proves quality discipline, traceability, change control, compliance documentation usability, and lifecycle readiness before you treat samples or pricing as decision drivers.
A “minimum evidence pack” should be short, current, and revision-controlled. It is not about collecting paper—it is about proving that reliability can be sustained at scale.
Minimum Evidence Pack (recommended baseline):
- Quality system scope and traceability approach (how batches map to field issues)
- Outgoing test coverage summary (what is tested, when, and how failures are handled)
- CAPA maturity evidence4 (a sanitized example or process overview)
- Revision-controlled technical documentation (installation, cleaning, service, limitations)
- Change-control artifacts (PCN/ECN template, lead time policy, substitution rules)
- Regression validation approach (what gets re-tested when changes occur)
- Lifecycle policies (supply continuity commitments, EOL notice period, migration approach)
- Service process overview (RMA workflow, escalation path, spares strategy)
If suppliers cannot provide clear, current, revision-controlled evidence, sustaining reliability during scaling becomes difficult even if initial samples look strong.
Verify integration stability the way it fails in real rooms
Interface specifications and resolution claims do not guarantee stable operation under actual clinical deployment conditions requiring comprehensive real-world validation.
Integration validation must reproduce real-room triggers using the same signal chain and operating conditions you will deploy, because failures often appear during switching, movement, recording, and environmental stress—not during ideal demos.
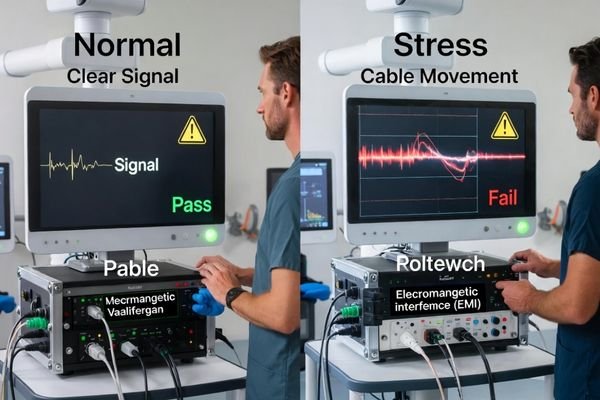
Validate with the exact chain you will operate: sources, extenders, switchers, recorders, cable lengths, and mounting arrangement. Then observe behavior during triggers that commonly cause issues:
- Input switching and recovery time
- Recording activation and overlay toggling
- Cart movement, cable flex, and connector stress
- EMI-heavy conditions (especially in OR environments)
Signal Chain Validation Under Operational Stress
The validation goal is not “does it display an image,” but “does it remain locked and predictable under stress.” Confirm the display does not show intermittent black screens, repeated re-lock events, or inconsistent behavior when the chain renegotiates.
Real-World Trigger Testing and Performance Assessment5
OR and endoscopy validation should also include motion clarity and perceived latency checks during rapid movement scenarios. Multi-source environments should include switching frequency and recovery behavior checks. Ensure the supplier can support this validation method with guidance, troubleshooting support, and repeatable acceptance criteria.
Test multiple units to detect unit-to-unit and batch variation early
Single sample validation cannot reveal consistency issues that affect fleet reliability and long-term operational performance across multiple installations.
Test multiple units per configuration—ideally across different production periods—to detect variability early, because variability is what turns deployments into ongoing troubleshooting.
A practical starting point is at least 2–3 units per configuration. For higher-risk deployments, expand the sample set and include different production periods or batches when possible. Diagnostic fleet validation should confirm calibration behavior and QC workflow repeatability across units. OR validation should confirm that lock stability and perceived latency feel do not vary meaningfully between units.
Consistency checks6 should focus on what affects operations and training: predictable interface behavior, stable rendering behavior, and repeatable acceptance outcomes across multiple units.
Evaluate serviceability, spares, and escalation paths before you need them
Service infrastructure and support capabilities determine operational reliability more than initial product performance specifications throughout equipment lifecycles.
A supplier is only as reliable as its service model: warranty ownership, RMA execution, turnaround targets, spares availability, and escalation to engineering resources when issues are intermittent or systemic.
Use a simple verification checklist:
- Warranty ownership and who executes RMA logistics
- Repair/replace turnaround targets7 that match your region and downtime tolerance
- Spares strategy (local vs central stock, lead times, critical parts coverage)
- Escalation path to engineering for root-cause analysis and corrective action
- Evidence of closure behavior (how recurring issues are prevented)
This is where “reliability” becomes real: the fastest way to reduce downtime is to confirm processes and accountability before you need them.
Lock reliability into contracts and SLAs with clear change governance
Contractual frameworks transform supplier performance expectations into enforceable commitments that prevent reliability degradation over time.
Contracts should convert your scorecard into enforceable terms and define change governance so mid-cycle substitutions or firmware changes do not silently break fleet consistency.
Structure terms into four practical blocks:
- Acceptance and warranty8: acceptance criteria, warranty scope, and RMA workflow
- Change governance: PCN lead time, approval rights for critical changes, “no silent substitution” definition, regression expectations
- Lifecycle: supply continuity window, EOL notice period, and migration support
- Governance: KPI reporting cadence, escalation path, regular reviews (QBR), and corrective actions
Keep optional risk clauses (financial stability, backup sourcing expectations, IP protections) short and program-specific so they do not distract from the core reliability controls.
Use a pilot as a decision gate, not a formality
Well-designed pilot programs provide definitive validation of supplier capabilities under actual deployment conditions rather than ceremonial approval processes.
A pilot should be a decision gate that proves repeatable results, usable documentation, and predictable support response under the same conditions you will run after rollout.
Pilots should replicate deployment reality: same mounts, cables, intermediate devices, workflows, and triggers. Define outputs in advance and keep them concise:
- Acceptance checklist with pass/fail criteria
- Issues log with closure timelines and escalation behavior
- Validated baseline configuration and re-validation triggers
A pilot passes when results are repeatable across multiple units, documentation is usable for acceptance and maintenance, and the supplier’s response process is predictable.
Red flags that predict unreliable suppliers
Systematic identification of warning signs prevents costly partnerships with suppliers who cannot deliver reliable long-term support throughout equipment lifecycles.
Red flags are patterns that predict downtime and audit risk: unclear authorization or warranty ownership, missing revision-controlled documentation, vague change control, unstable lead times, weak spares strategy, and inconsistent batch deliveries.

Treat certificate-only compliance as a warning sign if the supplier cannot provide usable installation/cleaning/service guidance or explain how revisions are controlled. Treat unclear escalation paths as a warning sign when issues require engineering involvement. These patterns rarely improve after scaling—they usually become more expensive.
Conclusion
Medical display supplier selection becomes predictable when you treat it as a governed process: weight criteria by use case, define measurable KPIs, demand a minimum evidence pack, validate real-room integration stability with multi-unit testing, and lock expectations into SLAs and change-control terms. This approach reduces procurement risk, improves fleet stability, and supports reliable operations through scaling and lifecycle transitions.
Our experience at Reshin shows that suppliers are most reliable when evidence is revision-controlled, acceptance is repeatable, and support response is predictable over time. When selection is driven by verifiable processes rather than impressions, long-term reliability becomes manageable and scalable.
✉️ info@reshinmonitors.com
🌐 https://reshinmonitors.com/
-
Exploring the benefits of structured evaluations can help you reduce surprises and improve fleet consistency. ↩
-
Understanding signal-chain stability is crucial for ensuring reliable performance in clinical settings, especially during critical procedures. ↩
-
Learning effective measurement techniques for MTTR can enhance your repair processes and customer satisfaction. ↩
-
Exploring CAPA maturity evidence helps in grasping how organizations manage corrective actions and improve quality systems effectively. ↩
-
Exploring effective methods for testing can enhance your validation process and improve performance in critical environments. ↩
-
Exploring consistency checks will provide insights into maintaining operational stability and improving training outcomes. ↩
-
Understanding these targets can help you minimize downtime and improve operational efficiency. ↩
-
Understanding Acceptance and warranty is crucial for ensuring project deliverables meet quality standards and client expectations. ↩